How to set up 3-way merge tool for git and p4 with vimdiff
Encountering a situation to resolve a merge conflict that is harder than usual as well as taking longer time won’t come in very often. Most of merge conflicts I have resolved can be easily done by looking at a linear 3-way diff view alone without a need to look at each separate content of each file.
A linear 3-way diff (that I’d like to say) is as follows
<<<<<<< HEAD
(text from your version)
||||||| cab9282
(text from original version)
=======
(text from their version)
>>>>>>> feature_branchGit 3-way linear diff format (need git config --global merge.conflictstyle diff3). cab9282 is just an example of SHA1 for git hash.
>>>> ORIGINAL file#n
(text from original version)
==== THIERS file#m
(text from their version)
==== YOURS file#m
(text from your version)
<<<<Perforce 3-way linear diff format (by default)
But in a more complicated case, it is not enough to just take a look only at a linear 3-way diff format above. It’d be so helpful to see content in base, yours and theirs version. With the help of colorizing diff between each version, this would reduce time and reduce number of guesses from the one who would be merging.
Take a look at the scenario below

Imagine if changes from A to (B, C) deviates itself very far if compared to changes from A to D. Then to-be-merge-result of E would require much of effort. Sometimes automatic merge mechanism results in a mess state that is totally hard to guess which chunk either from base, yours or theirs version should be picked?? You know, sometimes chunk of codes just cut, and inserted out of nowhere. This is result from too deviated away, and much of work has been done around the same lines of code in two different branches. More full-fledge 3-way merge is needed in this case.
If you use GUI merge tool, and you probably are happy with it. Then the information listing here might not be too attractive to you. But if you’re command line-based users. Please read on.
A guide below is to set up your merge tool to use vimdiff with git, and perforce (p4.exe/p4 binaries). Note that we are not going to talk about how to use it here, but just setup.
Git
git config --global merge.conflictstyle diff3Git doesn’t use
diff3format by default. So when there is a merge conflict, conflict chunks will only show in diff2 format; which might not be enough. This command will set to show in diff3 style.git config --global merge.tool gitmergetoolgit config --global mergetool.gitmergetool.cmd "gitmergetool \"\$BASE\" \"\$REMOTE\" \"\$LOCAL\" \"\$MERGED\""Escape
$in order to not let terminal interpret it as environment variable (if executed on Unix/Linux based terminal). This will set our customized merge tool namelygitmergetoolto execute the command as set.sudo touch /usr/local/bin/gitmergetoolAdd the following content into such file via your favourite text editor
#!/bin/bash # script to accept arguments sending in from git mergetool # # Base is $1 # Remote (or Theirs) is $2 # Local (or Yours) is $3 # Merged is $4 vimdiff -c "wincmd J" -c "windo set wrap" "$4" "$3" "$1" "$2"According to git mergetool - Options, git will send in arguments in order of
$BASE,$LOCAL,$REMOTE, and$MERGEDrespectively in which we pass in from ourmergetool.gitmergetool.cmdaccordingly. Then inside our shell/bash script, some rearrangement is done. This is to arrange our window layout (wincmd Jto place the first window downward). In additional to enable word wrap for all window (disabled by default for vim’s diffmode).sudo chmod +x /usr/local/bin/gitmergetoolTo make sure our script is executable.
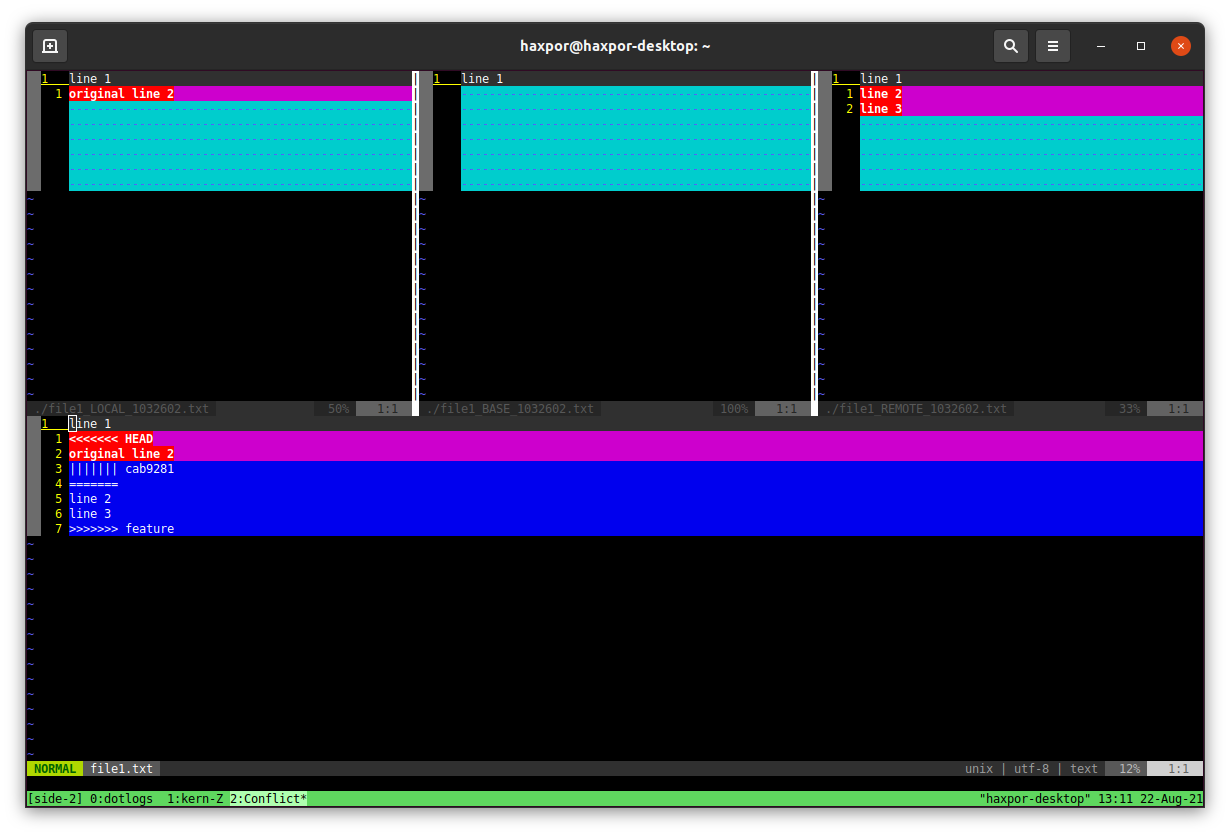
We are done here. When you attempt to merge, and result in merge conflict. It usually displays the following lines
Auto-merging file1.txt
CONFLICT (content): Merge conflict in file1.txt
Automatic merge failed; fix conflicts and then commit the result.Then you can execute git mergetool. It will show like in the following screen
Perforce
Nowadays you can use p4.exe/p4 through WSL to work with both Windows-based, and Linux-based project. The guide listed in this section is based on WSL.
As you are aware,
p4binary needs to understand platform specific path. It has issue like this if try to use WSL-basedp4binary to work with Windows-based project. Anyway, WSL makes it easy to work across Windows/Linux platform now. So we can usep4.exeor switch to usep4when need easily. Better utilize it unless it is fully Linux-only platform.
Windows-base p4
p4 set P4MERGE="bash /usr/local/bin/p4merge_windowspath"This is a Windows specific way to set environment variable via registry for merge program to be used. Here we specify shell/bash script to intercept the arguments as same as we did for git.
sudo touch /usr/local/bin/p4merge_windowspathAdd the following content into such file via your favourite text editor
#!/bin/bash # this is to allow us to convert input Windows path to Linux path as sent in by # perforce. # Perforce sends arguments in order of base, theirs, yours, and resulting merge file. # # Base is $1 # Theirs is $2 # Yours is #3 # Merged is #4 vimdiff -c "wincmd J" -c "windo set wrap" `wslpath $4` `wslpath $3` `wslpath $1` `wslpath $2`The order of arguments sending in from
p4 resolvestated here which are base, theirs, yours, and merged file. As similar as we had with git, we set up window layout accordingly.Notice that we use
wslpath <path>to convert from Windows-based path into Linux-based path asvimdiffwe are using here is Linux-based through WSL.sudo chmod +x /usr/local/bin/p4merge_windowspath
We are done. After attempt to do p4 resolve, and have merge conflicts. It will prompt you what to do in which it will provide you with a chance to do merge per file i.e. m key.
It will execute merge tool as we set up above. It shows the same screen output as can be seen in git section. But the linear diff format is different.
Linux-based p4
- Add
export P4MERGE="bash /usr/local/bin/p4merge_linuxpath"into your~/.bash_aliases. source ~/.bash_aliasessudo touch /usr/local/bin/p4merge_linuxpathAdd the same content of
/usr/local/bin/p4merge_windowspathas seen in Windows-based p4 section above into/usr/local/bin/p4merge_linuxpathbut the last line should bevimdiff -c "wincmd J" -c "windo set wrap" $4 $3 $1 $2As you can see, no need for
wslpathas the path is already in Linux-based path.sudo chmod +x /usr/local/bin/p4merge_linuxpath
Closing
To fasten your process, you can use my repository haxpor/mergeconflict_repo which can trigger merge conflict right after merging from feature branch into master. My apology, I don’t have any perforce setup for you to test as it’s different beast for server to setup. Anyway with that repository, it’s enough to validate your vimdiff setup.
First published on August, 22, 2021
Written by Wasin Thonkaew
In case of reprinting, comments, suggestions
or to do anything with the article in which you are unsure of, please
write e-mail to wasin[add]wasin[dot]io
Copyright © 2019-2021 Wasin Thonkaew. All Rights Reserved.